
Hierarchical Partial Pooling for Georgia Runoff Elections
Updated: Jan 5, 2021 (last update before results?)
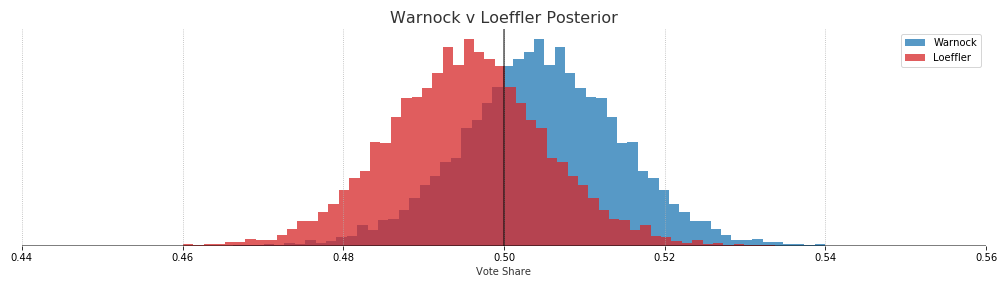
Warnock: 69.3% - Loeffler: 30.4%
Ossoff: 58.6% - Perdue: 41.4%
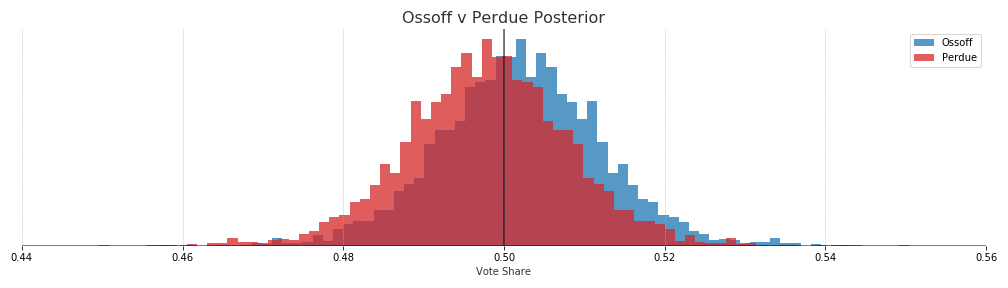
This is a good time to point out that a win probability of around 60% can be misleading. At least in my case I take that too confidently. Looking at the amount of overlap between the two distributions makes it look like Warnock v Loeffler is moving away from being a coin toss.
Estimated Vote Shares
| Candidate | Mean | 80% Interval |
|---|---|---|
| Ossoff | 50.2 | 49.0 - 51.5 |
| Perdue | 49.8 | 48.5 - 51.0 |
| Warnock | 50.5 | 49.2 - 51.7 |
| Loeffler | 49.5 | 48.3 - 50.8 |
Methods
The probabilities were derived from a hierarchical partial pooling model of voteshares using PyMC3. The hierarchical model assumes that there is some latent (unobservable) true vote share for each candidate. We can get glimpses of that vote share with the polls, however each pollster will have its own distribution of estimated vote share due to sampling error, house effects or other some other error. Therefore we model the results of each pollster as some offset from the true unobservable vote share.
Assume that the number of voters for each candidate in a survey follows the Binomial distribution.
![]()
Each pollster then has a probability of success for a given candidate which is modeled by a beta distribution where the parameters are given by the estimated state vote share modulated by some pollster offset.
![]()
The offset for each pollster is given by taking the exponential of the half normal distribution. These will roughly correspond to the numbers of successes and failures for the candidates in the polls. We know this value can not be negative which is why half normal is used. An exponential distribution could also work here.
![]()
Finally, the thing that we actually care about. The latent vote share of Georgia voters. This is modeled by a beta distribution and initialized by the results of the November election.
![]()
Essentially what is happening here is that we are estimating distributions for each pollster about what results we should expect from them. Assuming that those pollster distributions are influence by the actual state distribution as well as some pollster specific offset. Finally, the actual state vote share distribution is driven by the prior and each of the polls.
An alternative to the partial-pooling model would be a complete pooling model. In this case we would try to predict the same parameter for vote share for all of the pollsters. This parameter would then be the expected state wide vote share. As each pollster is trying to measure the same population there is some validity to that approach. However, I think its more realistic to allow each pollster to vary but have them anchored to some population distribution (which is what partial-pooling does).
Win Probabilities
After estimating the distribution of vote share for each candidate we get the probability of victory by the proportion of estimated voteshare that is greater than each candidates opponent.
Data
Using the polling data provided by 538. Each poll was weighted by an exponential decay function that reduces the weight the further out the poll was from the election date. Polls that are two weeks out are weighted 0.75, 30 days out are weighted 0.5, and 60 days out would be 0.25.
When pollsters produce multiple polls, only the most recent poll was used.
Priors
The priors for each model are set by the vote shares from the November election.
However some decisions had to be made for the Warnock-Loeffler prior because there were other Democrats and Republicans on the ballot for that race. Therefore the total Democrat and Republican voteshares were used rather than just the normalized voteshares for Warnock and Loeffler. We assume that republican voters that come back for the runoff race are likely to vote for Loeffler if their preferred republican candidate is no longer on the ballot. Using the normalized ratio between only Warnock and Loeffler would result in Warnock having an advantage in the posterior (roughly 60%).
Pollster Effects
Interestingly, if we plot each of the pollster distributions the model tends to push the median voteshare slightly towards the priors when compared with the actual poll results. However each of the actual results are still well within the expected ranges of each pollsters distribution. This is the result of using a regularizing prior. The model is skeptical of polls results that deviate too far from the results of the November election. We can see that the size of the correction changes as the poll results get further away from the prior and as the uncertainty in the polls changes.
Plot the actual polls results in orange and the estimated poll distribution in gray. If we don’t see any orange is because the estimated median completely overlaps the actual results. The dashed blue line is the maximum a posteriori estimate of Democratic vote share.
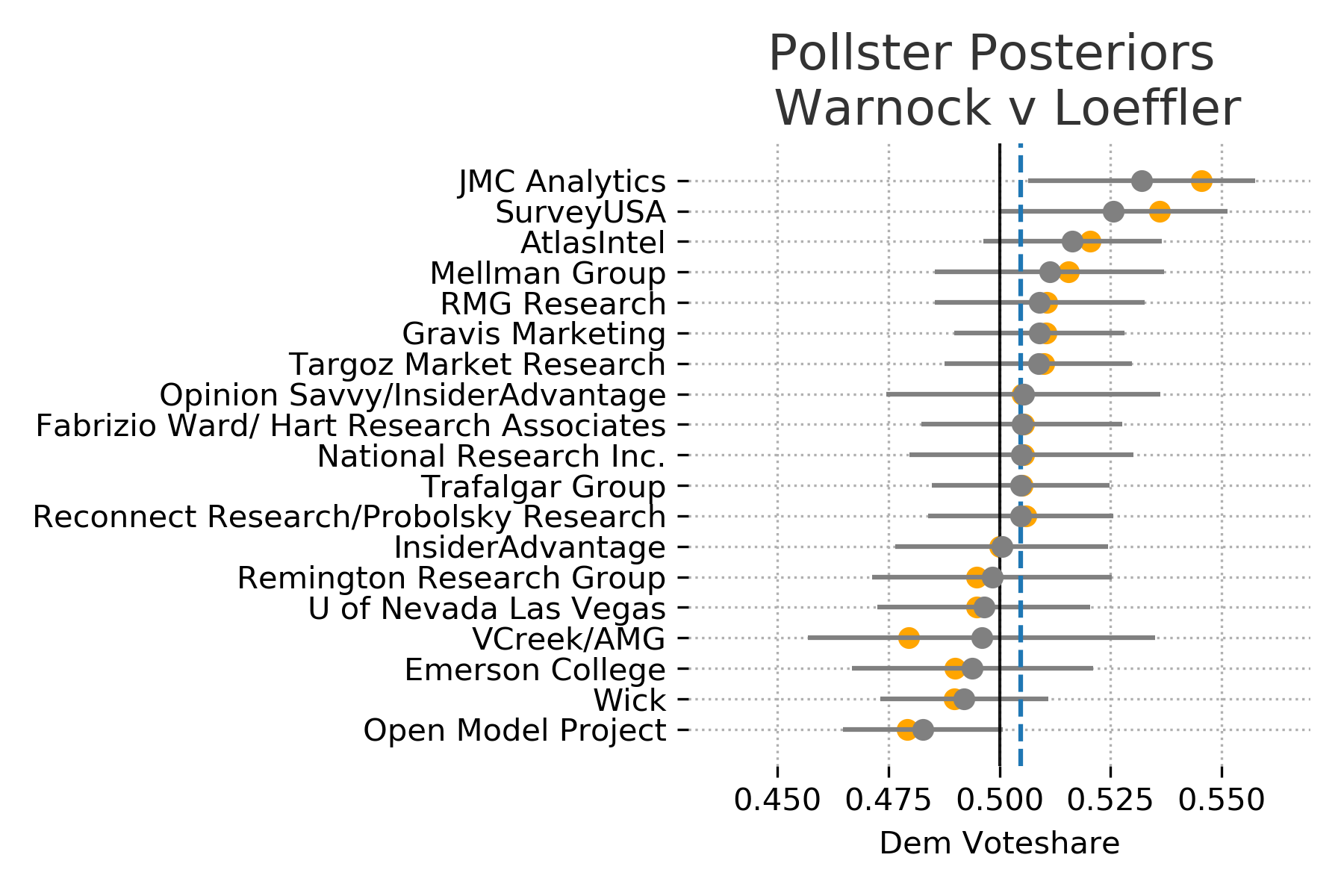
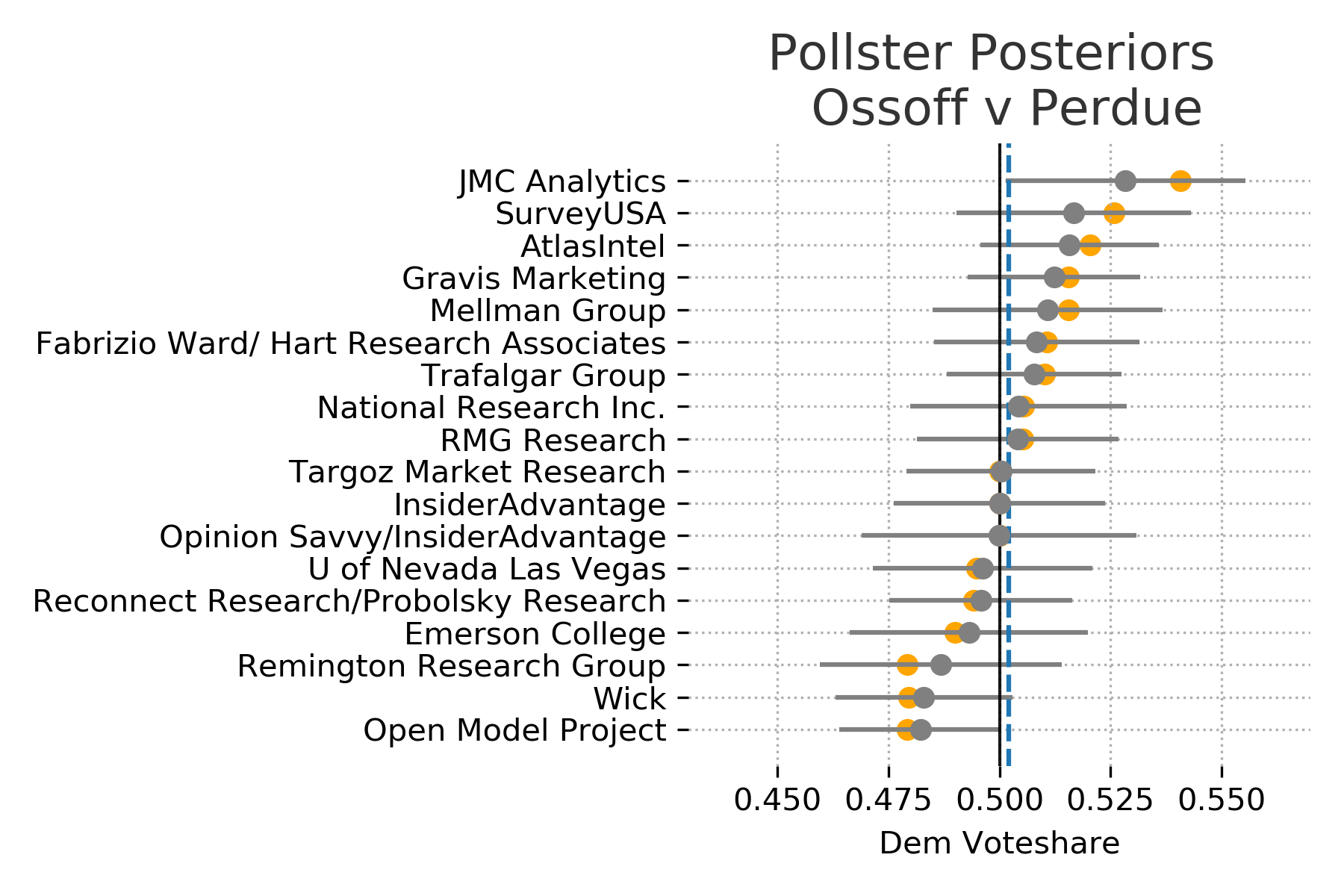
Tuning Prior
By using the beta distribution as our prior we can tune how much of an impact it has on the posterior distribution. A simple way of doing this is to use the sum of the two parameters for the beta distribution, alpha and beta. The larger the sum the more “peaky” or informative the prior, which gives it more weight in the final distribution. In other words, the more sure we are that the outcome of the Nov 2020 election will repeat in the runoff the more weight we want to put into the prior.
There are good reasons to weight the prior highly here. The election was recent, the turnout is much larger than any poll sample size, and it was an actual election not a survey.
However, turnout in the runoff could be much different and public opinion can change.
In the end a sum of parameters equaling 50 was used, which gives us a prior with swings in vote share of about +-1 15% from the Nov 2020 outcome. This uncertainty is quite large but it allows the polls to drive most of the posterior. With a sum of parameters at 1000 the priors are much tighter and quite a bit more resistant to change along with the polling data.
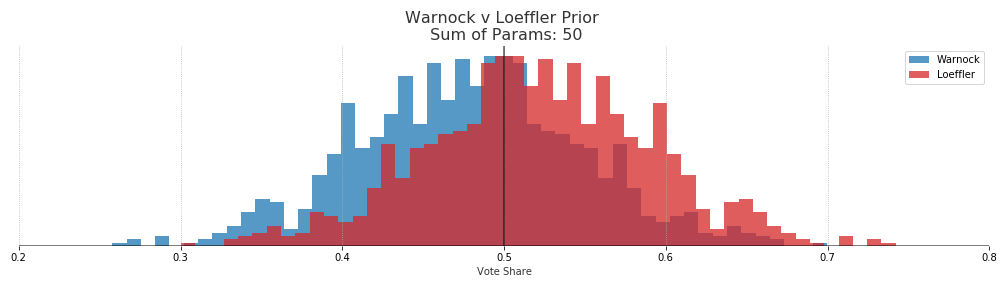
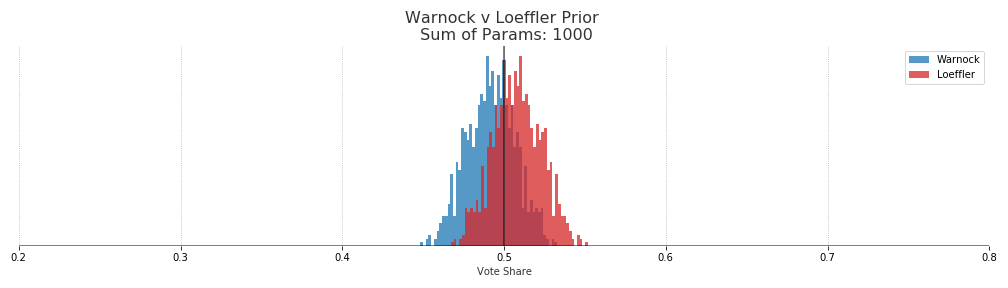
In terms of probabilities of election outcomes, if we use the sum of paramters of 1000 prior we get a roughly 70% win probability for both republican candidates. That would essentially be saying that the results of the November election will be repeated and we shouldn’t put too much weight on the polls.
How much weight to put on this prior is certainly up to debate and people more versed in Georgia politics can have that debate. Ideally I would have consulted with someone more versed Georgia politics for this decision.